昨天我們成功獲得了一個作者所有作品的ID,今天來生成網址並抓下他們。
尷尬的是再看了一次發現有更好用的json檔,裡面可以直接抓下來一個ID有多少圖。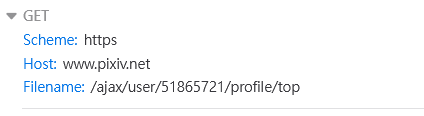
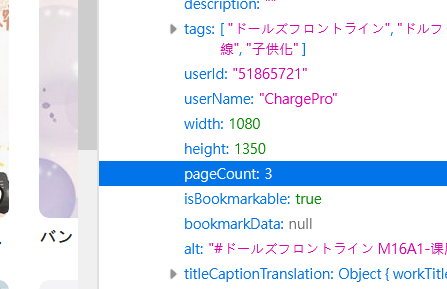
原本我寫的辦法是暴力蒐的,之後有時間再重寫好了。
總之先以原本方法繼續。
建議先用os套件建個資料夾來存東西,使用前記得先import os。
os.makedirs(authorID, exist_ok=True)
authorID就是資料夾名,我自己是都用pixivID當資料夾名。
exist_ok則是該資料夾存在時是否進行取代。
我們昨天抓的json下有幾個區塊會有ID,我是習慣只抓'body'下'manga', 'illusts'這兩項底下的。
pixiv要存到比較高清的圖需要轉換一下網址,具體可以參考這篇
然後一個畫作ID可能有多張圖,格式似乎也不太一定。
所以轉完後會再後面再加p0, p1...再拿png,jpg這兩種格式嘗試到讀不到網頁為止。
具體實作會變挺大一坨的,裡面基本上都是字串處理和try, expect就不多做著墨了。
對了,這塊可以使用requests來爬,效率大概會好一點。
這裡的話就是session出場的地方了,因為會儲存資訊設定一次cookie就可以了。
雖然不太確定是不是必要的但可以先把剛剛selenium的cookie給塞進session裡。
cookies = driver.get_cookies() #從selenium裡取出cookie
session = requests.Session()
headers = {
'Users-agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86 64; rv:91.0) Gecko/20100101 Firefox/91.0'
}
for cookie in cookies:
session.cookies.set(cookie['name'], cookie['value']) #遍歷cookies並設定進session